-
[TIL] 스파르타) CS 강의 수강 (DB, DBMS)TIL-sparta 2024. 4. 30. 17:39
> MySQL이나 postgres, MongoDB등 몇 가지 DB를 사용해 본 적은 있지만 이론적인 부분은 배워본 적이 없었는데, 이번 강의 수강 및 추가적인 조사를 통해 원리와 개념을 좀 더 명확하게 정립할 수 있었다.
학습 키워드: database, DB, DBMS, file system, SQL, NoSQL, ACID
1. Database와 DBMS (Database Management System)
1) What is it?:
- 데이터베이스(DB)를 간단하게 정의하면 'collection of structured data', 즉 '구조화된 데이터들의 집합체' 라고 할 수 있다. 데이터가 주로 테이블의 형태로 저장되고, 데이터의 관리를 돕는 소프트웨어인 DBMS를 통해 데이터의 관리, 접근, 수정 등이 이루어진다.

관계형 DB 용어 정리 2) How does it work?:
- DDL, Data Definition Language: 데이터의 구조를 Schema라는 형태로 정의한다. SQL에서는 테이블을 대상으로 하는 CREATE, DROP, ALTER 등이 여기에 해당한다.
- DQL, Data Query Language: 데이터의 조회(SQL의 SELECT)에 사용된다.
- DML, Data Manipulation Language: 데이터를 수정(SQL의 UPDATE), 삽입(SQL의 INSERT), 삭제(SQL의 DELETE)할 수 있다.
- DCL, Data Control Language: 접근 권한을 부여(SQL의 GRANT)하거나 회수(SQL의 REVOKE)할 수 있다.
- 그 외 아래 링크 참고
SQL | DDL, DQL, DML, DCL and TCL Commands - GeeksforGeeks
Unlock the power of SQL commands: DDL, DML, DCL, TCL, DQL with syntax. Explore this comprehensive guide to become proficient in SQL commands.
www.geeksforgeeks.org
3) Why use it?:
- DBMS 등장 이전부터 사용되던 단순한 FMS(File Management System) 방식으로는 데이터의 관계성 문제나 동시성 문제 등 관리, 접근, 변경에 난점이 많은데, 이러한 부분들이 DBMS를 사용함으로써 해결된다.
- Consistency: FMS에서는 파일 끼리의 관계성이 없어 여러 어플리케이션에서 똑같은 데이터를 서로 다른 파일로 관리하게 되는 일이 종종 발생하게 된다. DBMS에서는 단 한 개의 데이터를 여러 유저가 쉽게 접근할 수 있다.
- Sharing: 데이터의 공유가 불가능하거나 매우 복잡한 FMS와 달리 DBMS는 접근 권한이 있는 모든 프로그램이 데이터를 공유한다.
- Concurrency: 한 곳에서 수정된 정보를 잃어서 데이터의 불일치가 생기는 것을 anomaly라고 표현하는데, DBMS의 locking system이 이러한 anomaly 현상을 방지해준다.
- Searching: FMS에서 데이터를 찾을때는 '어떻게' 찾아올 것인지를 구현해야 한다면, DBMS에서는 자체적인 기능을 통해 유저가 '무엇'을 찾는지를 구체화하여 쿼리할 수 있다.
- Integrity: DBMS는 Schema 처럼 미리 정의되어있는 규칙 아래 데이터가 생성되고 관리되기 때문에 FMS에 비해 무결성이 향상되어있다.
- Security: FMS는 단순히 비밀번호만 이용하지만, DBMS는 자체적인 기능들과 알고리즘을 통해 데이터 보안을 유지한다.
- Interface & Management: DBMS는 관리를 위한 GUI등이 존재하고, 데이터가 중앙화(centralized, 한 공간, 한 컴퓨터나 한 데이터베이스에 보관된다는 의미)되어 관리하기가 비교적 쉽다.
- Backup & Recovery: 시스템의 crash 같은 돌발 상황이 일어나도 데이터를 안전하게 복구할 수 있다.
4) When to NOT use it?:
- 데이터를 다수의 사용자가 접근할 필요가 없을 때
- 엄격한 실시간 처리가 요구될 때
- 오버헤드가 너무 클 때
- 초기 비용이 너무 클 때
- 응용 프로그램이 잘 정의되어 있고 변경되지 않을 것으로 예상될 때
5) DBMS?:
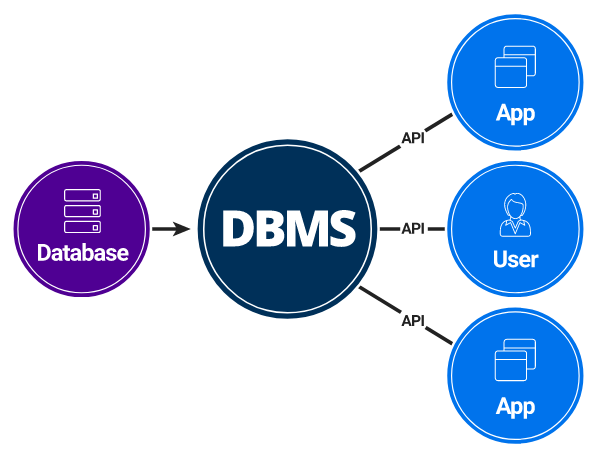
출처: 강의 노트 - DB를 효율적, 직관적으로 안전하게 사용할 수 있게 해주는 소프트웨어.
- DBMS의 구성에는 필수 요구사항이 존재한다. Oracle이나 aws 등의 사이트에서도 확인할 수 있다.
- 가장 많이 쓰이는건 RDBMS (관계형 DBMS)라고 한다. 모델이 간단하여 이용하기가 쉽다. 사용자는 API를 통해 원하는 것이 '무엇'인지만 명시하고 DBMS가 '어떻게' 찾을지를 결정한다.
- 관계형에서 '관계'란 colomn과 colomn을 연결하는 관계를 의미하며 연결되는 키의 개수에 따라 1:1, 1:N, N:N 으로 나뉜다.
6) Transaction:
- DB의 상태를 변화시키는 논리적 작업 수행의 단위. 결제 작업이면 결제 transaction 이 되는 식이다.
- Transaction의 필수적인 특징으로는 ACID (Atomicity, Consistency, Isolation, Durability) 성질이 있다.
- Atomicity: transaction에서 query operation을 single atomic operation, 즉 쪼갤 수 없는 atom 단위로 취급하여 처리하는 것을 말한다. 예를들면, query operation이 거부되거나 하는 경우 부분적인 수정이 일어나거나 하지 않고 완벽하게 원래의 상태로 돌아와야하는 성질을 의미한다.
- Consistency: transaction이 이루어 진 후 데이터가 consistent 해야함, 즉 Invalid한 데이터가 존재하면 안된다는 뜻이다.
- Isolation: 각 transaction의 고립 레벨로, concurrency로 인해 발생하는 문제(dirty read, repeatable read, phantom read)들에 대해 어떻게 대처할 것인지를 등급에 따라 네 단계의 standard isolation level (read uncommited, read commited, repeatable read, serializable)로 나눈 것이다. 한 transaction 블록이 실행될 때 해당 transaction이 접근 중인 데이터를 다른 쿼리가 읽거나 사용하는데 제한을 두도록 설정하여 데이터의 무결성을 보장하는데 도움을 준다. 아래 링크를 참고하자.
Transaction Isolation Levels in DBMS - GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
- Durability: commit이 완료되어 생성/수정된 데이터가 영속해야함을 의미하며, system failure (system crash 등)에서도 살아남아야 한다. Transaction 도중에 비정상적으로 종료되더라도 transcation log를 통해 복구할 수 있다.
2. SQL과 NoSQL
1) SQL:
- SQL은 Structured Query Language의 약자로, 관계형 DB를 통칭한다. MySQL, Oracle, MS SQL Server, Sybase, DB2 등이 대표적이다. 앞서 설명했던 DB 설명들이 대부분 관계형 DB에 해당한다.
2) NoSQL:
- NoSQL은 Not Only SQL 을 줄인 말로, 비관계형 DB를 의미한다. MongoDB, Redis, HBase 등이 대표적이다. 관계형 DB의 단점을 극복하기 위해 만들어진 구조로, Schema를 정의하지 않는다는 특징이 있다. 그 외 몇 가지 차이점을 종합하면 SQL에 비해 엄격함이 덜한, 융통성있는 형태라고 할 수 있겠다. NoSQL은 다음의 몇 가지 형태로 분류된다.
- Document-oriented: JSON과 유사한 형식으로 문서화한 데이터를 보관해준다. MongoDB가 여기에 해당한다.
- Key-Value pair: 속성을 Key, 연결된 데이터를 Value로 묶은 데이터를 배열로 보관한다. Redis, Dynamo가 여기에 해당한다.
- Wide-Column Store: key-value 형식과 비슷하지만, 데이터의 구조적 규모가 점차적으로 커질 수 있는, 즉 컬럼의 증가에 따른 유연성이 필요한 큰 데이터 분석에 자주 사용되는 형식이다. Cassandra, HBase가 여기에 해당한다.
- Graph: 자료구조의 Graph 형식과 비슷하게 데이터간의 관계를 구성하는 방식이다. Node에 정보를 저장하고, 각 노드를 잇는 Edge가 존재한다. Node와 Edge 모두 스스로를 설명하는 Property를 가질 수 있다. 쿼리 시 데이터 parsing이 필요해 커다란 document를 다룰 시 성능 저하가 있다고 한다. Neo4J, InfiniteGraph 가 여기에 해당한다.

이미지 출처: Oracle 3) Why use one over the other?:
- SQL을 사용하는 경우: 데이터의 ACID 성질을 준수해야할 때, 데이터의 구조가 일관적일 때 (일관적일 경우 SQL을 사용하는 쪽이 성능이 좋음)
- NoSQL을 사용하는 경우: 데이터의 구조가 거의 혹은 전혀 없는 대용량의 데이터를 저장해야할 때, 확장성이 중요할 때 (잦은 업데이트로 인한 DB의 다운타임 발생이 없어 빠른 서비스 구축에 용이)
- 개발 트렌드를 따라가는 경우도 있다.
--
REFERENCES:
[김태선 튜터] Computer Science 핵심쏙쏙 | Notion
CPU와 메모리
teamsparta.notion.site
> 강의 노트 // 5강. DB, 6강. DBMS
Advantages of DBMS over File system - GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
> GeeksForGeeks, 강의 내용 보강
SQL TRANSACTIONS - GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
> GeeksForGeeks, SQL Transactions 내용 보강
6.5830/6.5831: Lecture Notes and Assignments
[%title%] --> Lecture slides, lecture notes, videos, labs, problem sets, quizzes, and solutions will be posted here. Problem SetsDueLinks Problem Set 1 09/20/2023 [Handout] [Code] [Database (same as lab0)] Problem Set 2 10/10/2023 [Handout] Problem Set 3 1
dsg.csail.mit.edu
> OpenCourseWare, Lecture 1 Notes
What is a Graph Database?
A graph database is a specialized, single purpose platform for creating and manipulating graphs. Learn more about graph database types, benefits and use cases.
www.oracle.com
> Oracle, 내용 보강
728x90'TIL-sparta' 카테고리의 다른 글
[TIL] 스파르타) Project 3 - 2일차, Github Pull Request, review, 그 외 팀 프로젝트 관련 사항들 (2) 2024.05.02 [TIL] 스파르타) Project3 시작 (TMDB 팀 과제), Github Issues (2) 2024.05.01 [TIL] 스파르타) CS 강의 수강 (Thread) (0) 2024.04.29 [TIL] 스파르타) CS 강의 수강 (Process) (0) 2024.04.28 [TIL] 스파르타) CS 강의 수강 (CPU와 메모리) (0) 2024.04.27